projects
Robust and Efficient Deep Learning based Audio-VIsual Speech Enhancement
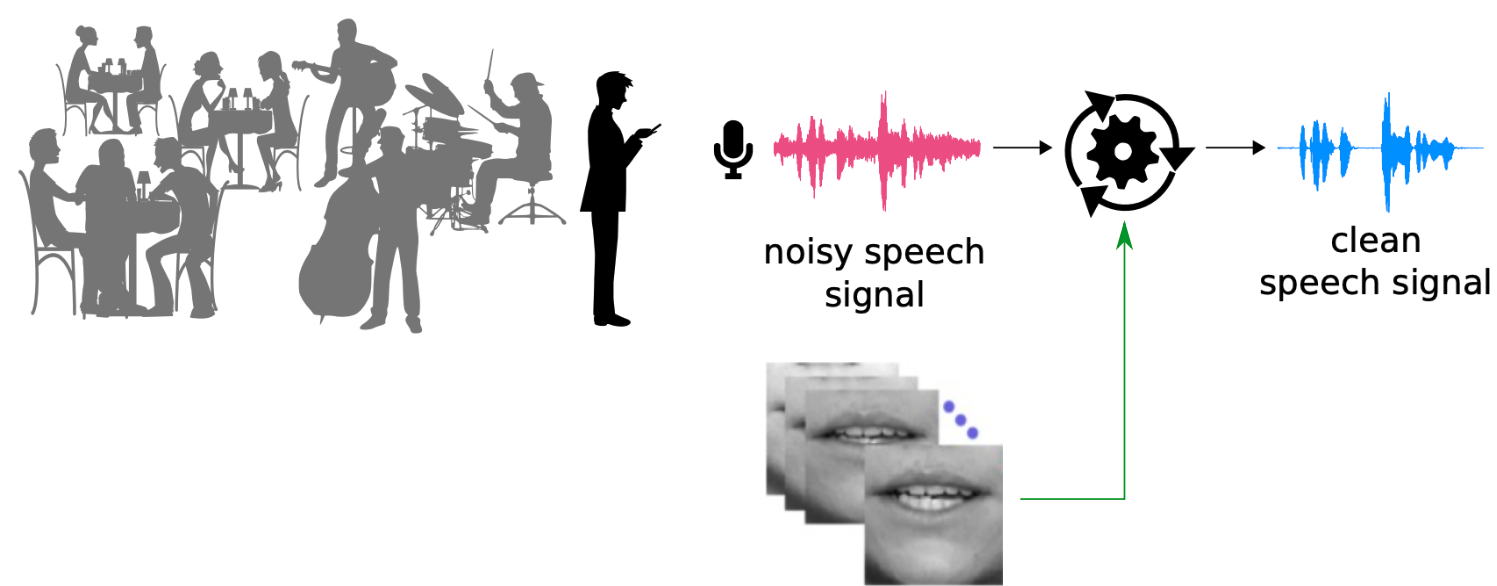
Job opportunities
- Postdoc/research engineer: If you hold [or are about to get] a PhD degree, in audio/speech processing, machine learning, computer vision, or related fields, or you hold a Master's degree, please email me with your CV, motivation letter, and transcripts attached.
Related publications
[1] Z. Kang, M. Sadeghi, R. Horaud, and X. Alameda-Pineda, Expression-preserving face frontalization improves visually assisted speech processing, International Journal of Computer Vision (IJCV), 2022. [Paper]
[2] M. Sadeghi, S. Leglaive, X. Alameda-Pineda, L. Girin, and R. Horaud, Audio-visual Speech Enhancement Using Conditional Variational Auto-Encoders, IEEE Transactions on Audio, Speech and Language Processing, vol. 28, pp. 1788- 1800, May 2020. [Code]
[3] M. Sadeghi and X. Alameda-Pineda, Mixture of Inference Networks for VAE-based Audio-visual Speech Enhancement, IEEE Transactions on Signal Processing, vol. 69, pp. 1899-1909, March 2021. [Code]
[4] M. Sadeghi and X. Alameda-Pineda, Switching Variational Auto-Encoders for Noise-Agnostic Audio-visual Speech Enhancement, in IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Toronto, Ontario, Canada, June 2021. [Slides, Poster]